

Sebastian Krzyszkowiak @dos@librem.one
- Homepage
- https://dosowisko.net
- Games
- https://dos.itch.io
- Holy Pangolin
- https://holypangolin.com
- Liberapay
- https://liberapay.com/dos
Hi, I'm dos. Silly FLOSS games, open smartphones, terrible music and more. 50% of @holypangolin; 100% of dosowisko.net. he/him/any. I don't receive DMs.
Joined Apr 2019
Sebastian Krzyszkowiak
boosted
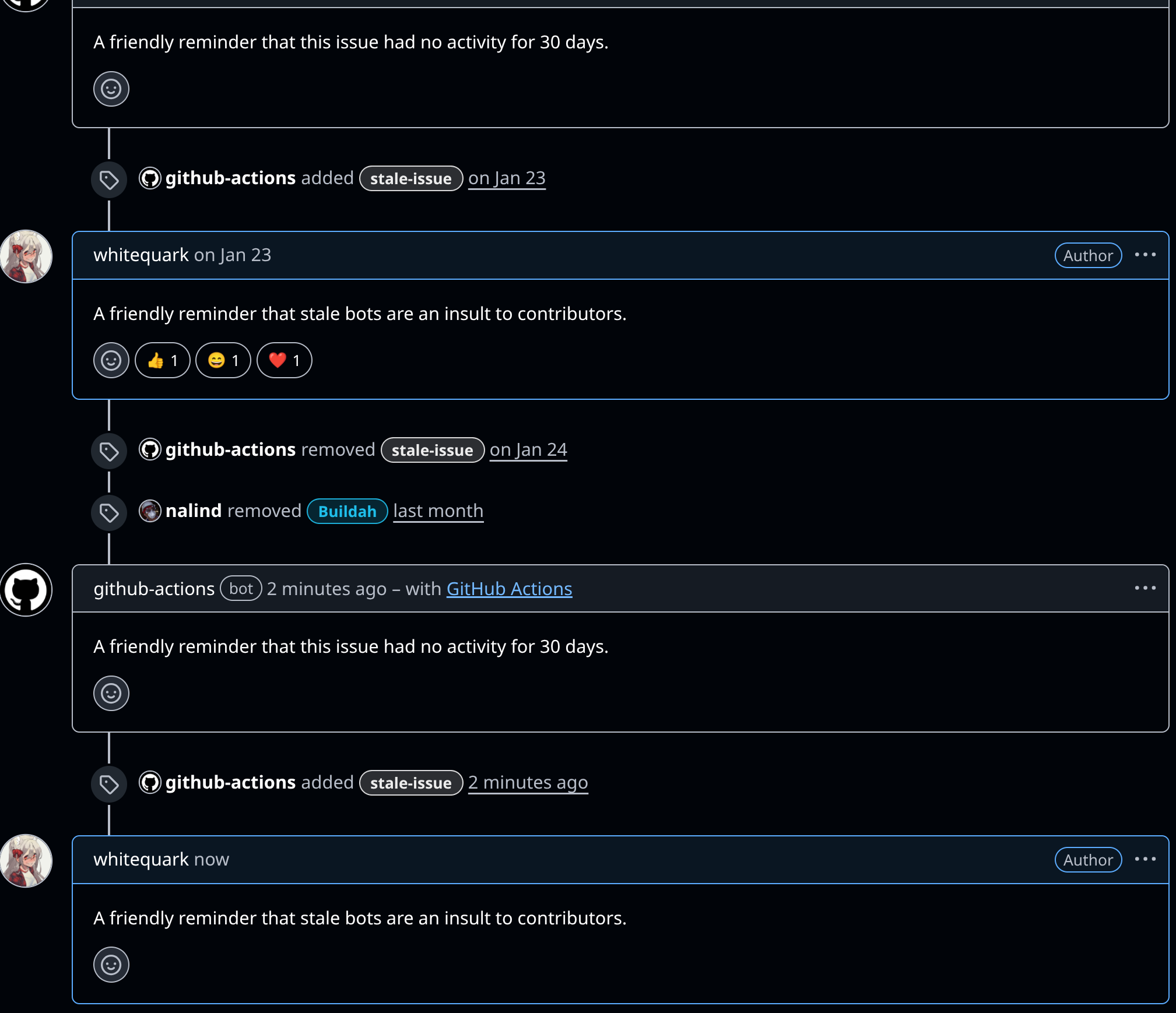
Q: And it will continue to work on non-Linux systems like FreeBSD?
A: Also correct.
Q: Why have I been hearing that KDE will force systemd down everybody's throats via Plasma then?
A: There are sad people who will do anything for attention and clicks, and will spread FUD and fake controversies to obtain them, including decontextualising comments on merge requests, stating as facts and official communications what are personal opinions, and finally straight up lie.
Don't believe the FUD.
3/3
{kind=link}
Despite of its enormous codebase it wasn't that hard to look around and find relevant stuff - the GTK layer is fairly thin. The hardest part was to compile it, but running distcc on a Steam Deck sped it up well 😄
We still need to:
- emit pointercancel when the browser takes the touch gesture over
- not change scrolling targets during scrolling just because a new one "flew" onto the cursor/finger
- have some thresholds to differentiate between vertical and horizontal scrolling
All my #WebKit merge requests have been merged. Now #WebKitGTK supports touch PointerEvent API, touch point coordinates are fractional, synthesized mouse events are unbroken and both WebKitGTK and WPE WebKit handle pointer capture and release according to the spec. This should considerably improve compatibility of #Epiphany (#GNOME Web) with touch interfaces.
There are still some more things to fix in there, maybe someone in #mobilelinux #linuxmobile community would like to give it a try?
Sebastian Krzyszkowiak
boosted
@marmarta @dos @camerontw Honestly the right answer to the question of who to disappoint is always going to be "the developers and designers of the thing." Our egos lead us to solve product problems over user problems, to end up with supporting a bunch of "use cases" no real user has.
Sebastian Krzyszkowiak
boosted
So, some great conversations at #fossback26 design. And some that really frustrated me. During the "how to bridge the gap between "ultra-nerdy" devs and designers" barcamp, someone said "we have to decide who to disappoint when making design decision", and someone else said "spoiler: it's the power users".
If our attitude towards #uxdesign is "fuck the power users", we'll never have good UX in open source.
It's funny how this phone keeps feeling faster as it gets older.
Looks like GTK is starting to get its renderer inefficiencies sorted out, as updating Flatpak runtimes has made Tuba smoother than ever 😄 #librem5
Sebastian Krzyszkowiak
boosted
{kind=link}
Sebastian Krzyszkowiak
boosted
{kind=link}
Sebastian Krzyszkowiak
boosted
{kind=link}
{kind=link}
Sebastian Krzyszkowiak
boosted
This is why GiovanH's blog article is a must-read.
People assume that accessible hacks of invasive systems will always exist, and users hacking their devices is to be expected.
THIS SHOULDN'T BE A NORM. THIS IS AN ARMS RACE AND WE'RE OUTMATCHED. /7
https://blog.giovanh.com/blog/2025/10/14/a-hack-is-not-enough/
{kind=link}
Sebastian Krzyszkowiak
boosted
a decade or so ago, I was writing a H.264 decoder (needed a custom one for stupid reasons which of course had to do with hardware reverse engineering).
the first order of business was to implement CABAC: the final entropy coding stage of H.264 (ie. the first layer I had to peel starting from the bitstream), a funny variant of arithmetic coding. the whole thing is quite carefully optimize to squeeze out bits from video frames by exploiting statistics. in addition to carefully implementing the delicate core logic, I also had to copy-paste a few huge probability tables from the PDF, which of course resisted copy-paste as PDFs like to do and I had to apply some violence until it became proper static initializers in C source code.
furthermore, testing such code is non-trivial: the input is, of course, completely random-looking bits. and the way bitstreams work, I’d have to implement pretty much the whole thing before I got to the interesting part.
so, a few hours later, I figured I’m done with CABAC and reconstructing H.264 data structures, and pointed my new tool at some random test videos. and it worked first try! the structures my program spit out looked pretty much as expected, the transform coefficient matrices had pretty shapes and looked just as you’d expect them to, and I was quite happy with that.
and then I moved on to actually decoding the picture from the coefficients, and this time absolutely nothing worked. random garbage on screen. I spent a long time looking at my 2D transform code searching for bugs, but couldn’t find anything.
and then it hit me exactly what “entropy coding” means. I implemented something that intimately knows and exploits the statistical properties of what video transform coefficients and other structures look like, their probabilities and internal correlations, and uses that to squeeze out entropy and reconstruct it on the other end. my “looks good” testing meant absolute jack shit: I could’ve thrown /dev/urandom into the CABAC decoder instead of actual H.264 video, and it would still look like good video data at this stage until you actually tried to reconstruct the picture.
and sure enough, it turned out I fucked up transcribing some rows from the PDF around a page break or something.
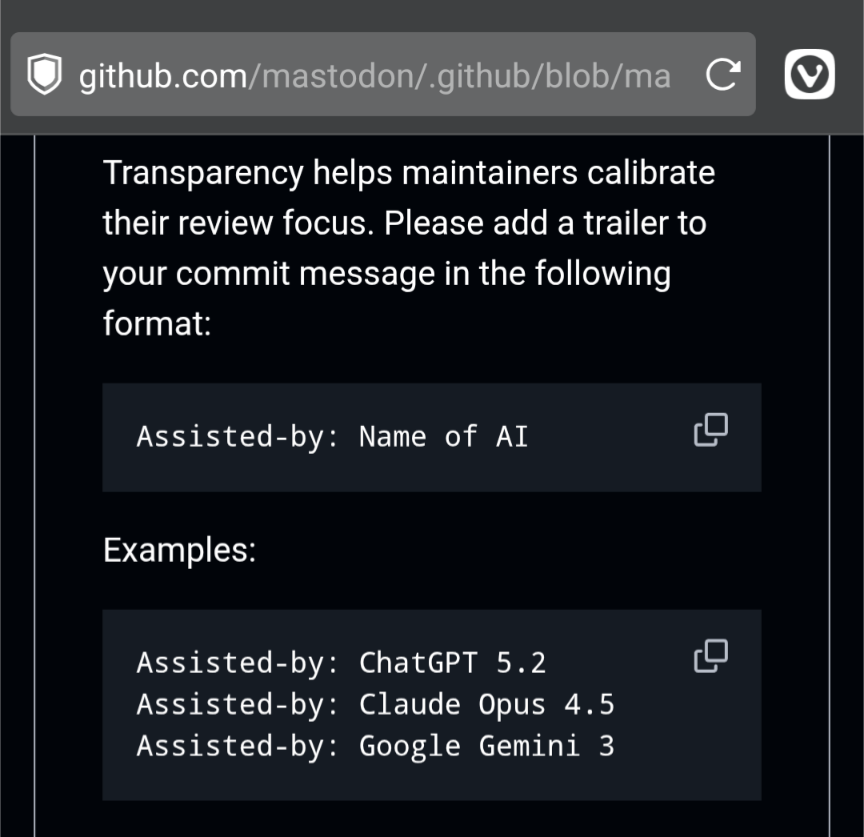
10 years later, I think of this experience every time I see a vibecoded pull request, or other manifestation of AI bullshit. all the right shape, and no substance behind it.
and people really should learn to tell the fucking difference.
I couldn't make any sense out of these #librem5 logs so I yielded to a developer higher in seniority who is now carefully analyzing the issue. #catsofmastodon
Sebastian Krzyszkowiak
boosted
This is a real time recording of my git server's web access logs. It's a constant stream of requests from "Claude" attempting to access every possible item on the site.
A couple of months ago, I set up a rule to return an error code for every request its user agent makes. It has not retrieved a single valid item for many, many weeks at this point. Every request is immediately and abruptly terminated.
It hasn't even slowed down as a result.
Tell me again how their operation involves "intelligence" of any kind.

Sebastian Krzyszkowiak
boosted
sometimes i’m thinking about becoming a vibe coder because i’m lazy as fuck but then i realize the models tend to be even lazier than me
- Homepage
- https://dosowisko.net
- Games
- https://dos.itch.io
- Holy Pangolin
- https://holypangolin.com
- Liberapay
- https://liberapay.com/dos
Hi, I'm dos. Silly FLOSS games, open smartphones, terrible music and more. 50% of @holypangolin; 100% of dosowisko.net. he/him/any. I don't receive DMs.
Joined Apr 2019
